一、为什么要蒸馏 Google SEO 文档

做工具站、流量站,本质上绕不开 SEO。
如果目标只是达到 70 分水平的 SEO 能力,最直接有效的方式就是系统阅读 Google 官方文档。但问题在于:
- 文档内容分散,阅读路径不连续
- 很难形成体系化认知
- 不方便在实际项目中快速调用
所以我当时的想法很简单:
把官方文档“产品化”,变成一个可以随时调用的知识系统,而不是一堆零散网页。
这一步的关键不是“学习”,而是“重构信息结构”。
二、整体方法:从原始文档到 SEO Skill
整个过程可以拆成 6 个步骤,本质是一条标准的信息蒸馏流水线。
Step 1:抓取官方文档结构
我先下了一个明确指令:
- 学习 https://developers.google.com/search/docs?hl=zh-cn 的全部内容
- 提取所有相关 URL 和对应概要
- 输出为结构化文件
这一步的目标不是拿全文,而是:
- 建立完整目录索引
- 明确内容边界
Step 2:批量获取全文内容

在拿到 URL 列表后,我继续做了一步拆解:

- 按 URL 逐个抓取页面正文
- 保留完整原始文本内容
- 不做任何删减
这里有一个关键点:
原始数据必须完整保留,这是后续“蒸馏”的原料。
Step 3:统一存储到本地知识库
所有内容最终统一存入本地目录(Obsidian):
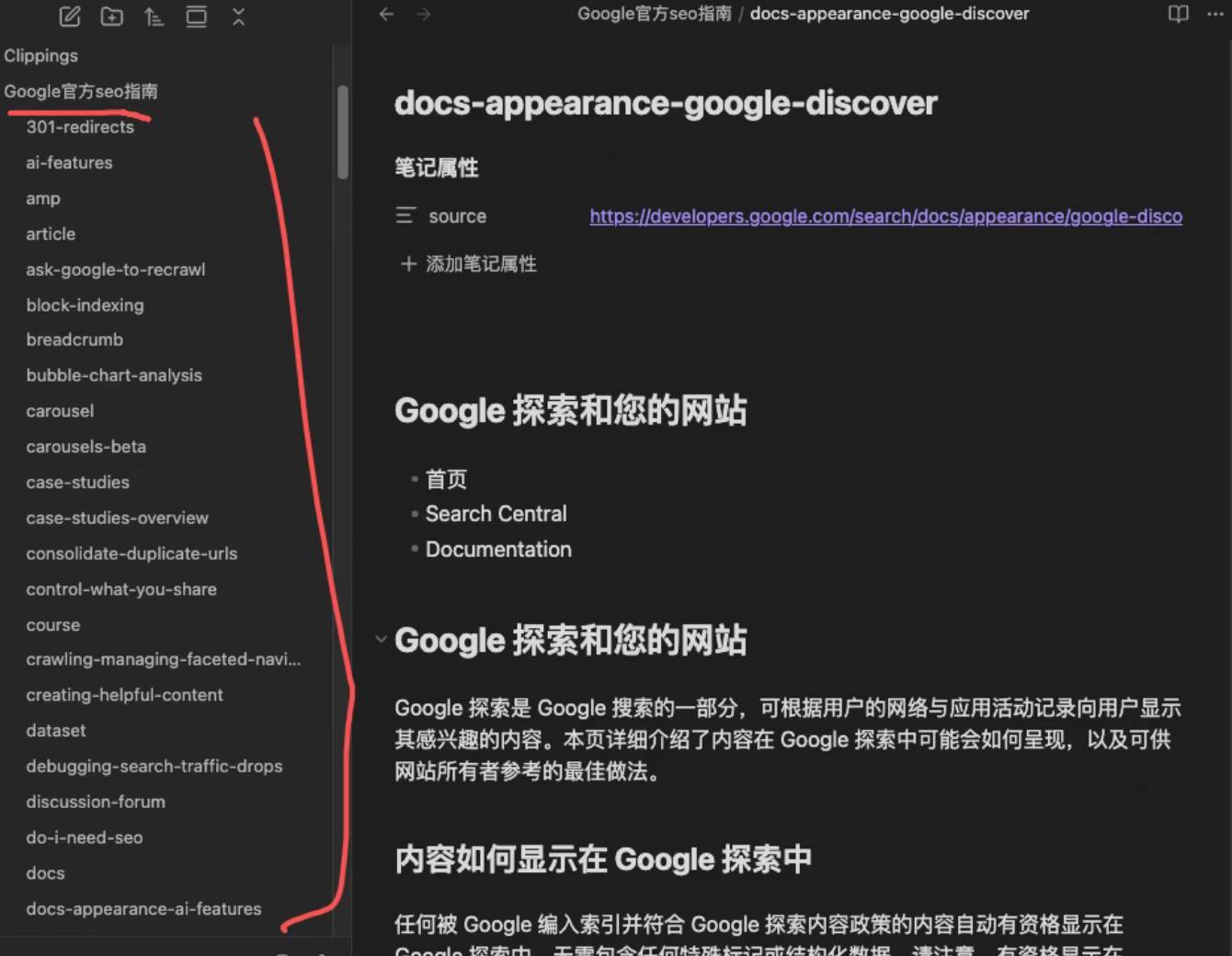
- 每个页面对应一个
.md文件 - 保持原始结构,不做过早抽象
- 作为“原始层数据”
到这一步,其实你已经拥有了一套:
完整可离线使用的 Google SEO 文档镜像库
Step 4:构建结构化目录体系
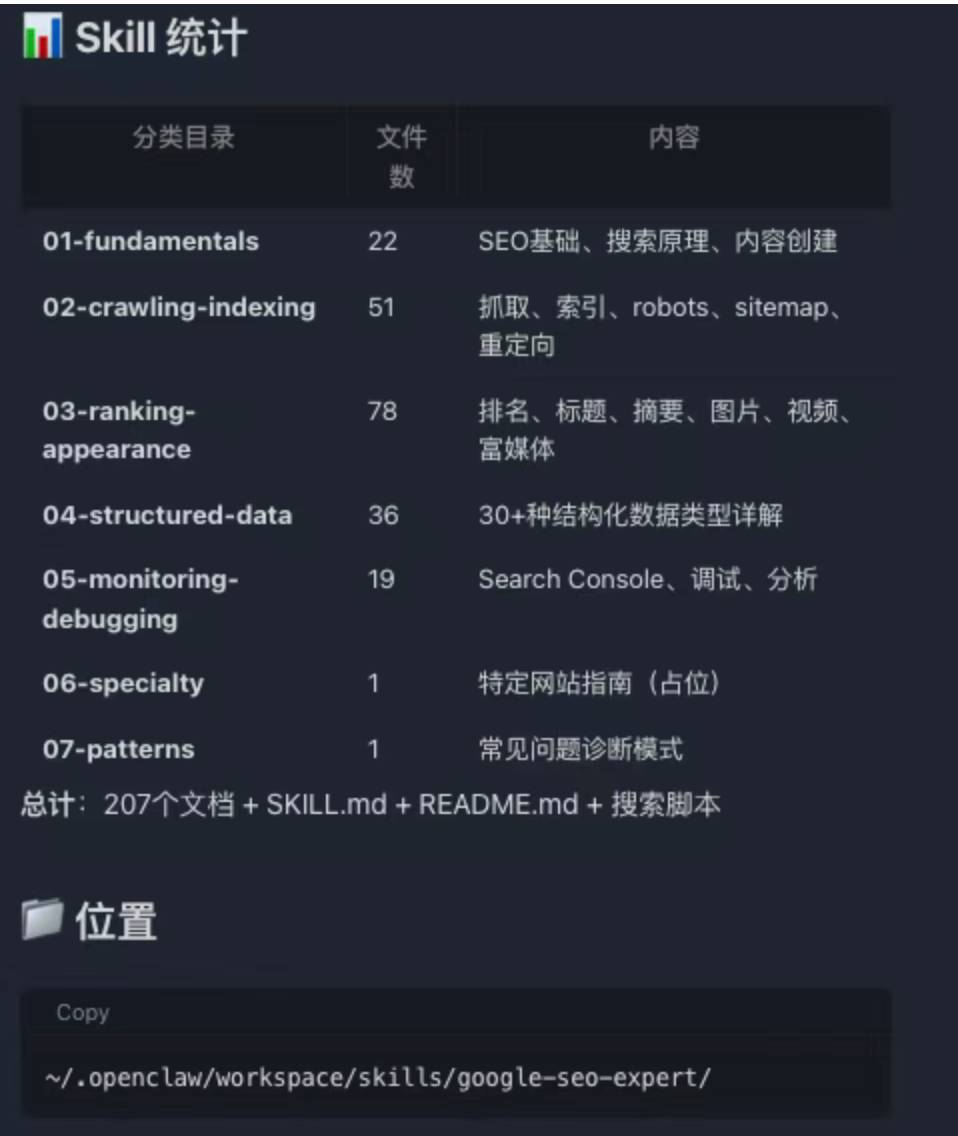
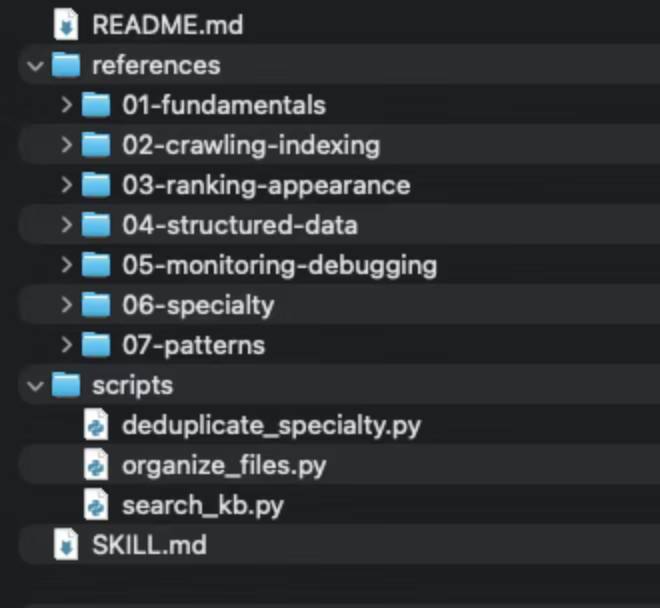
在原始数据之上,我做了第一次结构重构,形成清晰的分层目录:
知识库目录结构
references/
├── 01-fundamentals/(22个文件)
├── 02-crawling-indexing/(51个文件)
├── 03-ranking-appearance/(78个文件)
├── 04-structured-data/(36个文件)
├── 05-monitoring-debugging/(19个文件)
└── 06-specialty/(按需扩展)
各模块职责
-
01-fundamentals
- SEO基础概念
- 搜索引擎工作原理
- 内容质量标准
-
02-crawling-indexing
- 抓取机制(crawl)
- 索引控制(index)
- 技术SEO核心配置
-
03-ranking-appearance
- 排名因素
- 搜索结果展示形态
- 富媒体内容优化
-
04-structured-data
- Schema结构化数据
- 各类富结果定义(FAQ、Product、Review等)
-
05-monitoring-debugging
- 流量监控
- 问题诊断
- 工具使用(GSC、GA)
-
06-specialty
- 特定类型网站策略(按需扩展)
Step 5:内容蒸馏
有了完整知识库之后,我开始做“蒸馏”:


- 将冗长文档转为结构化 Markdown
- 提炼关键规则、约束、最佳实践
- 去掉冗余解释,但不丢失关键信息
这一层的目标是:
从“文档集合”升级为“可调用知识模型”。
Step 6:封装为 SEO Skill

最后一步是能力封装:
我把整个知识库作为上下文,构建了一个 SEO skill,可以直接用于问答,例如:
- 产品页如何展示价格和评分
- 多语言网站的最佳实现方案
这一步带来的变化是:
- 从“查资料” → “直接给答案”
- 从“知识库” → “工具能力”
三、最终产出能力
整个流程完成后,得到的是三层资产:
1. 原始数据层
- 完整 Google SEO 文档
- 本地 Markdown 存储
- 可长期复用
2. 结构化知识层
- 200+ 文档分层组织
- 明确分类和索引路径
- 支持快速检索
3. Skill 能力层
- 可对话调用
- 支持具体问题解答
- 可嵌入产品或工作流
四、这件事真正的价值
很多人看到这里,会觉得这只是“整理资料”。
但核心价值其实在这里:
1. 信息差重构
官方文档本身不是稀缺资源,但:
- 结构化能力是稀缺的
- 可调用能力是稀缺的
2. 可复制的方法论
这套流程可以迁移到任何领域:
- API 文档 → 开发助手
- 法律条文 → 合规工具
- 金融报告 → 投研系统
本质是同一件事:
把公开信息转化为结构化、可调用的能力。
3. 产品化路径
在这个基础上,可以直接延伸出产品:
- SEO诊断工具
- 自动优化建议系统
- 内容审核与评分工具
而且这些产品的核心竞争力,不在 UI,而在:
背后的知识蒸馏质量。
五、可落地的下一步
如果你要继续往前走,可以直接做三件事:
- 把这套知识库接入你的站点后台
- 做一个简单的 SEO 问答接口
- 增加自动检测功能(如页面结构分析)
优先顺序建议:
- 先做问答能力(最快见效)
- 再做检测工具
- 最后做自动优化
六、总结
这件事可以用一句话总结:
不是在做 SEO,而是在做“SEO能力的封装与产品化”。
当你把一整套官方知识,从“阅读材料”变成“可调用能力”的时候:
- 学习成本下降
- 使用效率提升
- 同时具备了产品雏形
这也是独立开发者在信息时代最值得反复做的一类事情。